
User documentation
Introduction
From version 13.1r0 the Harlequin Core can be configured by using JavaScript Object Notation (JSON) files. While the Harlequin Core continues to support PostScript configuration files, JSON configuration (config) files provide a more universally accepted and widely supported syntax that is familiar to many OEMs and thus easier to use. The SDK also includes a set of JSON schema files for JSON config file validation that helps the OEM when creating or modifying existing JSON configs within a JSON schema-aware editor. These JSON schema-aware editors validate the JSON syntax in real time, while also often providing IntelliSense feedback to the user on the options available as the JSON file is being edited.
JSON offers an alternative to using PostScript to configure the Core; it is not intended as a replacement. JSON config files that follow the provided config schemas can be used to configure the Core via the -c command-line option, just like the PostScript config files. The JSON config files can be edited using any editor but we highly recommend using a JSON aware editor that is also JSON schema-aware.
This document addresses JSON "files", but we anticipate that many JSON objects for job-level configuration will be generated dynamically and supplied to the Core when that job is added to the job queue (rather than being written to disk).
A file supplied as the operand to a -c argument on the clrip command line (or equivalent may be supplied as JSON, but JSON is not supported for Page features (that is, using the -F command-line argument). The expectation is that configuration fragments to be used in that way will be selected using jsonrun in the primary configuration file if there is a desire to encode them as JSON.
The implementation of JSON configuration in Harlequin Core SDK 13.1r0 is a technology preview primarily for feedback to Global Graphics.
To learn about JSON and its syntax
The following internet links are excellent resources to learn about JSON if you are not familiar with JSON syntax. You can skim them as a start:
- https://www.w3schools.com/js/js_json_syntax.asp
- https://en.wikipedia.org/wiki/JSON
- https://www.json.org/
To learn about JSON Schema and its syntax
The following Internet link is an excellent resource to learn about JSON schema if you are not familiar with its syntax and purpose. You can skim it to begin with.
A quick start by example
The SDK is shipped with a number of example JSON config files that replicate the functionality of their PostScript counterparts in the SW/TestConfig directory. These example JSON config files can be found in the SW/TestConfig/JSON directory.
To get going quickly, let us have a look at a simple example JSON config file shipped with the SDK. If you look at the contents of the following file:
SW/TestConfig/JSON/CMYKComposite300dpi.json
you begin to get an idea of what JSON config files are about.
To use the above JSON config file as a configuration when ripping jobs, it can simply be used as follows:
clrip -c JSON/CMYKComposite300dpi.json MyTestFile1.pdf MyTestFile2.ps MyTestFile3.jpeg
The above produces .tif files in the same directory as the jobs being ripped. Those familiar with using clrip with PostScript config files recognize that the -c option on clrip can now be used to specify either a PostScript config file or JSON config file. The preference for which syntax to use is yours.
To start developing your own JSON config file configurations, copy one of the files in SW/TestConfig/JSON to develop your own JSON config file. Your JSON config file should remain in the SW/TestConfig/JSON directory. You can then do the following:
clrip -c JSON/MyConfig.json MyTestFile1.pdf MyTestFile2.ps MyTestFile3.jpeg
JSON config files must be suffixed .json or .JSON.
At this stage, look at all the example files in the SW/TestConfig/JSON directory.
Find a decent JSON editor
Before starting to create JSON config files, Global Graphics highly recommends picking a decent JSON schema-aware editor, as the SDK includes JSON schema files for Harlequin JSON config files. Visual Studio Code (free) is one such editor and in our opinion is the best for editing JSON files on macOS, Linux, and Windows. Other editors are available for download from the Internet; the following table lists a sample of such editors:
Name | URL | License |
Visual Studio Code | Free | |
Visual Studio | Free for non-commercial use | |
Liquid Studio 2020 | Commercial | |
Eclipse | Free | |
XML Spy | Commercial |
Editors that understand JSON schema when editing JSON files will tell you about syntax errors while editing and validating the keys and their value contents to a certain degree. This is useful, as while the RIP reports syntax errors when loading JSON config files, it does not do any schema validation.
Visual Studio Code is excellent at showing issues in your JSON files; it is available for Windows, macOS, and Linux. Global Graphics highly recommends it.
Writing JSON configuration
The write/test/debug rinse and repeat cycle
Start with copying one of the provided examples to your own configuration, keeping your file in the SW/TestConfig/JSON directory so that the schema files can be found relative to this new file.
The best way to then develop Harlequin JSON config files is to edit/test/debug and repeat.
- Make some minor changes to your config file using a JSON schema-aware editor.
- Check that the JSON editor you're using is not reporting any errors with your new JSON config file.
- Check that your JSON config file works with the RIP and that the output is as expected. For example:
clrip -c JSON/MyConfig.json MyTestFile1.pdf
and then check the output is picking up your changed settings.
If all is working OK, repeat steps 1 to 3.
Doing this incremental development approach of JSON config files helps you avoid spending a lot of time debugging.
A simple example on Windows using Visual Studio Code
Step 1. Copy one of the existing examples to your own copy. In this case, we copied CMYKComposite300dpi.json to MyCMYKComposite1200dpi.json so that we can make changes to that boilerplate configuration. The first change is to modify the resolution to 1200 dpi.
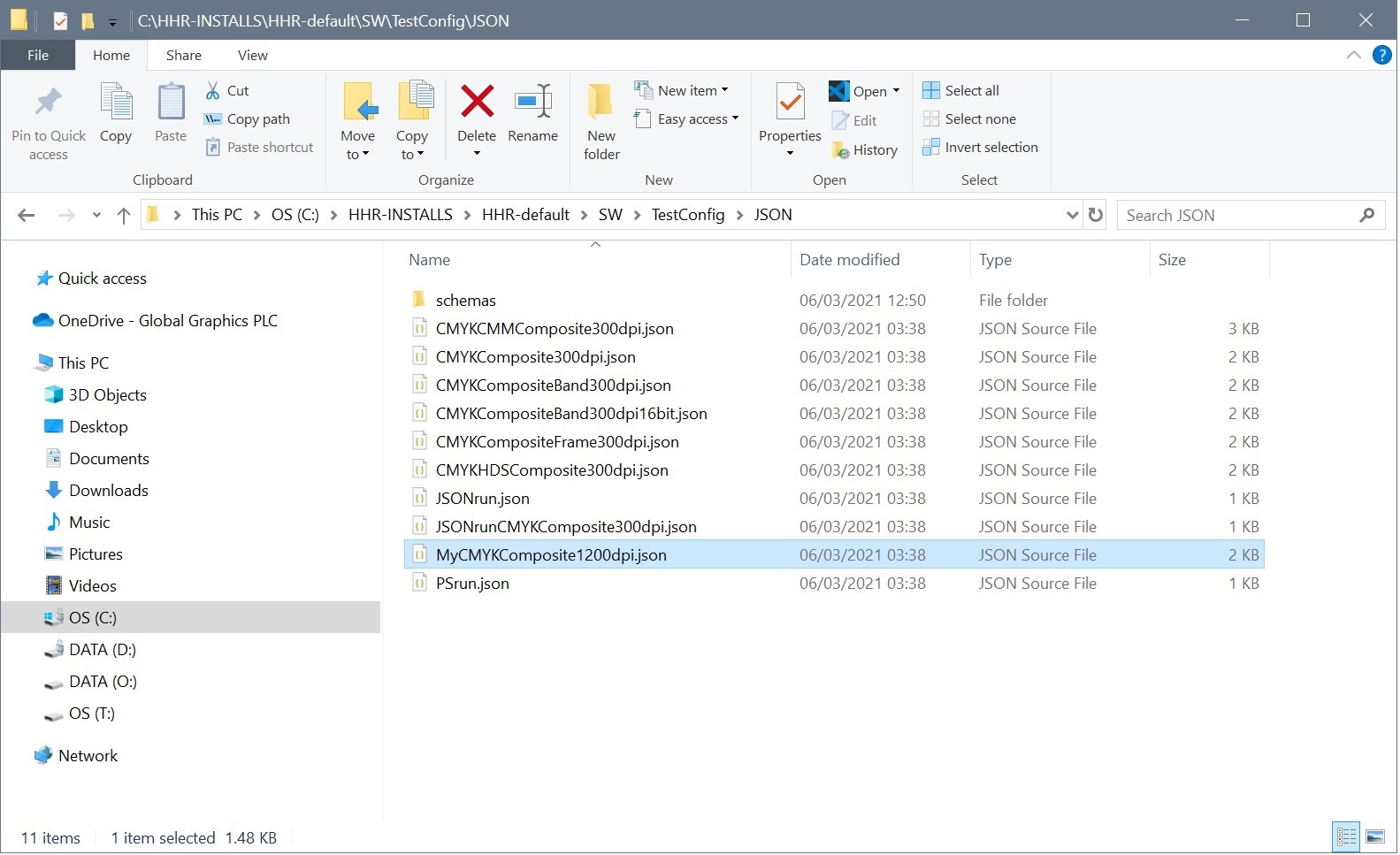
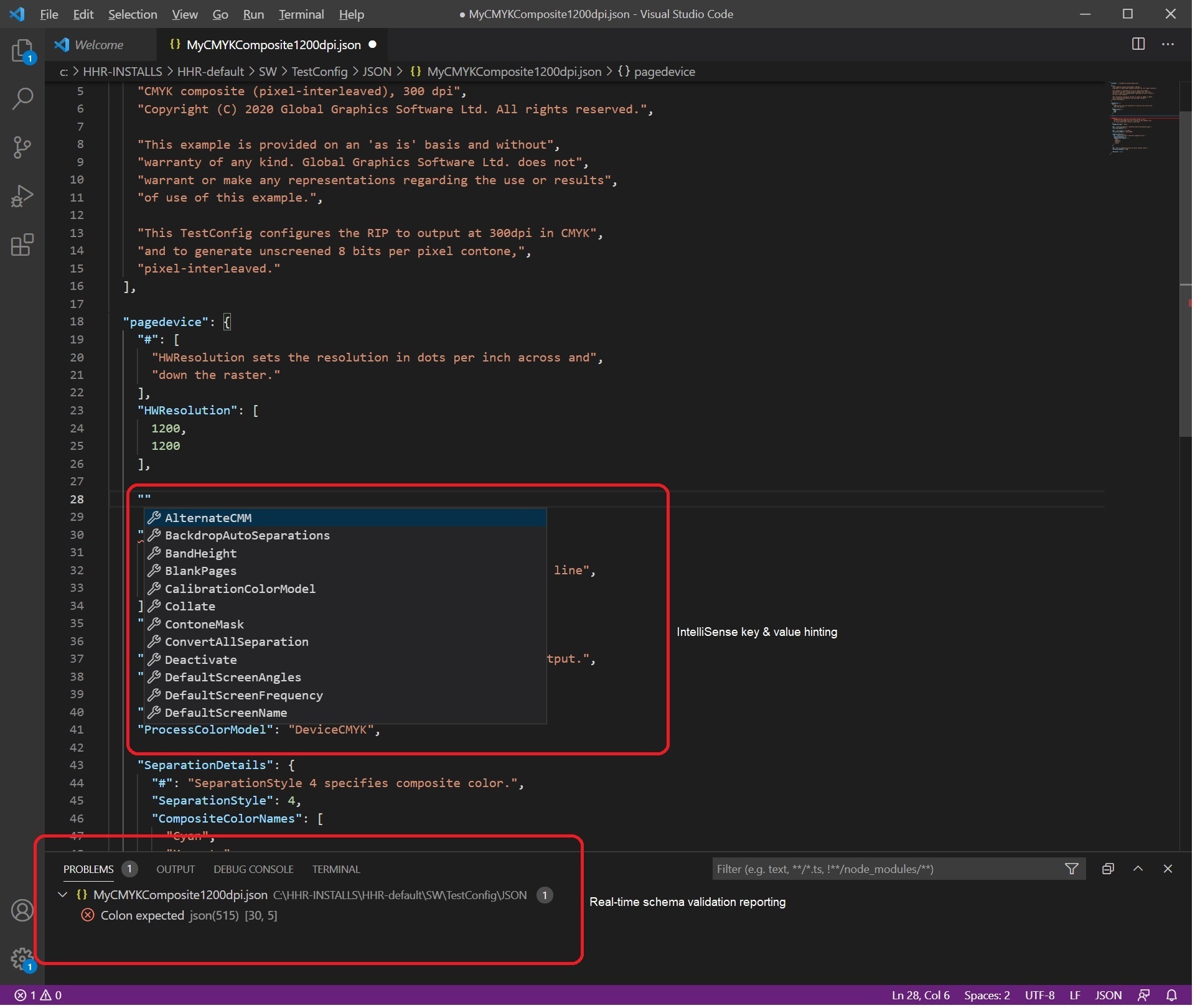
Step 2. Using Visual Studio Code, we changed the HWResolution to 1200 dpi, as shown below. We then started adding another key by typing "" as shown below. When doing that, Visual Studio code shows us a list of options for allowable keys, which it obtains from the JSON schemas. It also immediately shows a schema validation error. This is because we have yet to type in the : after the key name. This demonstrates that using a JSON schema-aware editor is very useful in avoiding errors in your JSON config files.
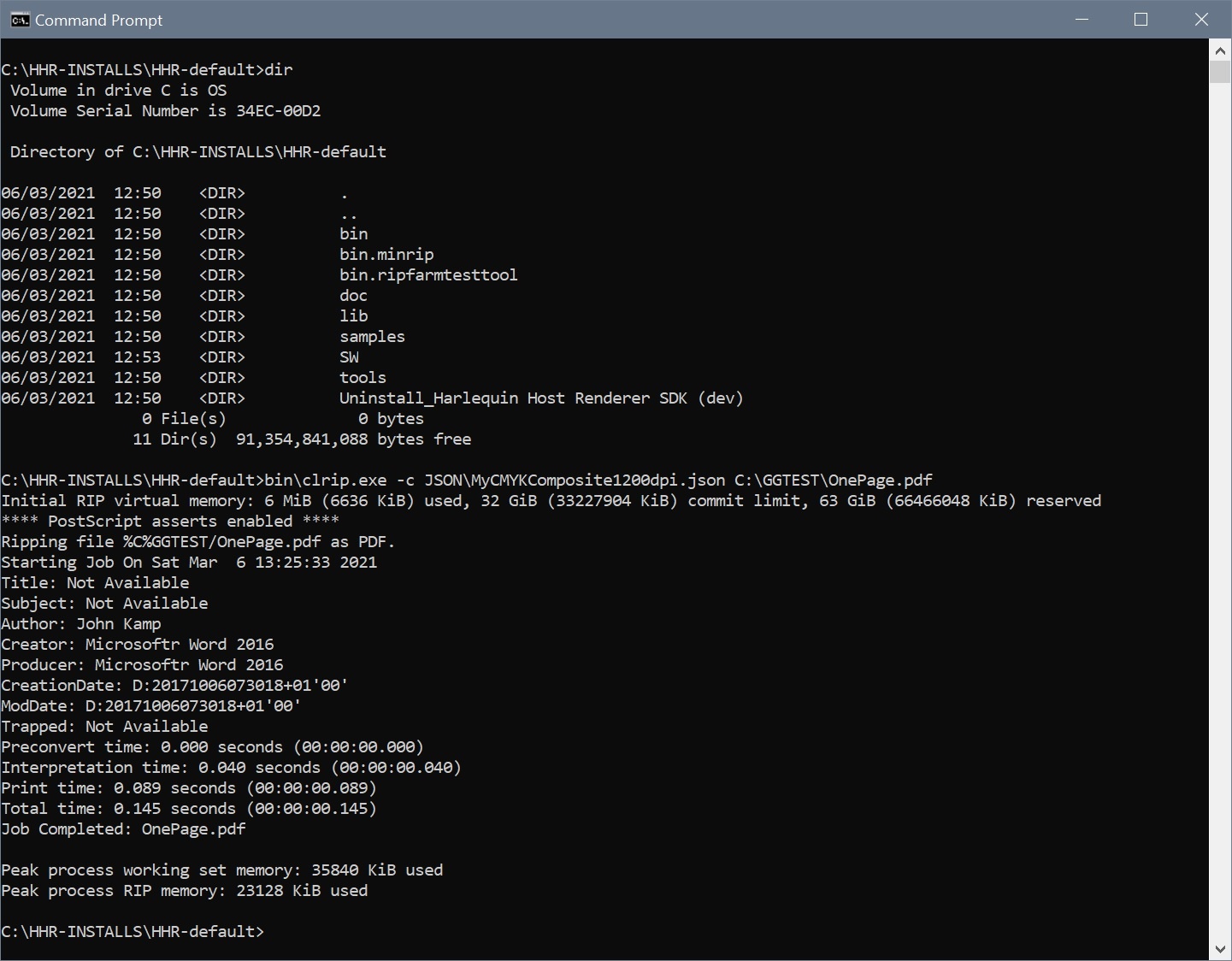
Step 3. Test your edited JSON config file using an installed clrip from the SDK and check that the output matches what you expect as per your JSON config. In the example below, the TIFF file C:\GGTEST\OnePage.pdf-1.tif would have been created using a resolution of 1200dpi.
Schema key ($schema)
When writing JSON config files it is good practice to validate your config files before using them with the Rip. This can be done by specifying a schema for your JSON config file via the $schema JSON keyword. The entry point schema file is called:
sw-config-schema.json
This file is the entry point for all supplied JSON schema files and is the only schema file that needs specifying in your JSON config files.
For example, use the sw-config-schema.json schema files as follows:
{
"$schema": "./schemas/sw-config-schema.json",
[config top-level keys follow]
}Because we distribute config schema files as part of SDK, it is useful to use a relative path from your JSON config file to the schema file. The above example assumes that the JSON config file is in the SW/TestConfig/JSON directory as the path to the sw-config-schema.json is a relative path and we distribute them in the SW/TestConfig/JSON/schemas directory.
If you encounter problems using a JSON configuration, please validate the JSON file against this schema before reporting to the Harlequin support team.
The JSON schema validation cannot report all issues in a config file that give rise to errors when the config is used in Rip. This most commonly happens when a combination of properties in the config is not allowed, especially when those properties are in different objects within the JSON.
Comment keys
Because the JSON syntax was designed and intended for data, it does not support comments as part of its syntax. Because of this omission, the Rip allows keys that start with a # and are optionally followed by a numeric number to be used as comments in JSON config files. This allows JSON config files to be annotated with useful annotations. The comment object can either be a string or an array of strings. The example JSON config file located in the SW/TestConfig/JSON/CMYKComposite300dpi.json file demonstrates this. A simple example follows:
{
"$schema": "./schemas/sw-config-schema.json",
“#”: “This is a one-line comment.”,
“#1”: [
“This is a two-line comment.”,
“This is the second line.”
],
[config top-level keys follow]
}Because JSON does not allow duplicate keys in a single JSON object, the numeric following # should be used to make the key unique as demonstrated in the above example. Different sub-objects in the JSON config tree can re-use comment keys; they only have to be unique in a particular object.
Comments of this form may be used in most JSON objects, but not all. If you hit unexpected errors, check the schema files and documentation; if in doubt, remove comments to see if that fixes the problem.
Best practice when writing JSON config files
While developing Harlequin JSON config files, we found the following to be useful guidelines:
$schemashould be the first entry inside each JSON config file.- Do not use
$commentin JSON config files; use only schema files. - Annotate your JSON config files with comments using
#[0-9]+key names. - Validate your JSON config files using a JSON schema-aware editor before submitting the RIP.
A working example
A complete example config that works is shown below. This file can be found in the SW folder in the directory SW/TestConfig/JSON and can be invoked with the command line:
clrip -c JSON/CMYKComposite300dpi.json <MyTestFile.pdf>
{
"$schema": "./schemas/sw-config-schema.json",
"#": [
"CMYK composite (pixel-interleaved), 300 dpi",
"Copyright (C) 2021 Global Graphics Software Ltd. All rights reserved.",
"This example is provided on an 'as is' basis and without",
"warranty of any kind. Global Graphics Software Ltd. does not",
"warrant or make any representations regarding the use or results",
"of use of this example.",
"This TestConfig configures the RIP to output at 300dpi in CMYK",
"and to generate unscreened 8 bits per pixel contone,",
"pixel-interleaved."
],
"pagedevice": {
"#1": [
"PageBufferType specifies the output format to use.",
"It can be overridden with the -o option on the command line",
"to clrip except when -nrips is also used."
],
"PageBufferType": "TIFF",
"#2": [
"HWResolution sets the resolution in dots per inch across and",
"down the raster."
],
"HWResolution": [
300,
300
],
"#3": "InterleavingStyle 2 specifies pixel-interleaved output.",
"InterleavingStyle": 2,
"#4": "The output is in CMYK.",
"ProcessColorModel": "DeviceCMYK",
"SeparationDetails": {
"#": "SeparationStyle 4 specifies composite color.",
"SeparationStyle": 4,
"CompositeColorNames": [
"Cyan",
"Magenta",
"Yellow",
"Black"
]
},
"#5": "We're outputting 8 bits per pixel contone raster.",
"ValuesPerComponent": 256,
"Halftone": false
}
}Filenames
Filenames in JSON (jsonrun, psrun, and others) must be specified using the PS syntax (this is a temporary limitation in the technology preview). For example, a full pathname can be specified on Windows as follows:
%C%/users/paul/mytestfiles/myfile.txt
Windows drive letters MUST be specified in uppercase, as shown in the previous line.
The SW folder can be specified with %os% (for example, %os%/TestConfig ).
PS filenames use a forward slash as the directory separator.
Configuration filenames on the command line (-c <Filename>) use the OS syntax for filenames. For example:
clrip -c C:\MyConfigs\CMYKComposite1200dpi (on Windows)
clrip -c /home/donald/MyConfigs/CMYKComposite1200dpi (on Linux)
Top-level JSON config properties
The JSON config file is made up of a single JSON object in which each top-level key represents an area of RIP configuration.
Where there is an obvious mapping, JSON keys and values are spelled and written with the same case as their PostScript equivalents. This should help OEMs who have existing PostScript configurations move to JSON configurations. New JSON keys and values that do not have a direct PostScript mapping are written using camel case: ForExampleLikeThis. If there is an acronym in the name, the acronym is written using all uppercase letters. The exception to this rule is that all the top-level keys are always written in lowercase letters. This is to keep consistency with the PostScript equivalents (such as pdfparams and pagedevice).
The JSON top-level keys are:
color
The reference for what keys are allowed in this top-level object is specified in the schema file sw-color-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
JSON keys for color operations are: BlackGeneration, Calibration, named colors, HqnImportICC, and HqnWhite.
| Key | Default | Value description |
|---|---|---|
AddToActiveNamedColorOrder | String, or array of strings. Add named color database(s) to the active named color order. | |
AddRelWhiteToCIEABCColorSpaceCopy | An array of three reals. Set the relative white point in any CIEBasedABC colorspace. | |
AddToIgnoredSpots | An array of strings. Add spot colors to the IgnoreSpots named color database. | |
BlackGeneration | Configuration for the HqnBlackGeneration procset. | |
Calibration | Interpolation array, or array of four interpolation arrays, to pass to setcalibration. | |
DeleteFromActiveNamedColorOrder | String, or array of strings. Remove named color database(s) from the active named color order. | |
DeleteFromIgnoredSpots | An array of strings. Remove spot colors from the IgnoreSpots named color database. | |
HqnInitializeL1Separation | Boolean. Set up level 1 separating procedures. | |
HqnInitializeL2Separation | Boolean. Set up level 2 separating procedures. | |
InitWhite | Configuration for the HqnWhite procset. | |
InstallICCCommentHandlers | Boolean. Install/remove ICC comment handlers.
| |
NamedColorDatabase | Definition of a named color database. | |
PushCalibration | Create a calibration set. | |
PushCalibrationUpdate | Update a calibration set. | |
RenderingIntent | Set the rendering intent. | |
SetIgnoreSpotsForceUpperCase | Boolean. Set the ForceUpperCase flag on the IgnoreSpots named color database. |
control
The reference for what keys are allowed in this top-level object is specified in the schema file sw-ctrl-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
The control key is an arbitrary grouping of keys used to configure miscellaneous RIP control items. For Harlequin 13.1r0 the keys are:
| Key | Default | Value description |
|---|---|---|
OverrideAsserts | JSON interface to OverrideAsserts in the HqnAssert procset. | |
DCSstandardSetup | JSON interface to DCSstandardSetup in the DCSCommentParser procset. | |
InitContour | JSON interface to InitContour in the HqnContour procset. Note that the operand structure has been significantly changed for 13.1 in support of better JSON validation. See the Harlequin Extensions Manual for more detail. | |
LoadErrorHandler | JSON interface to LoadErrorHandler in the HqnErrorHandler procset. | |
HqnImageSetImageDefaults | JSON interface to HqnImageSetImageDefaults in the HqnImage procset. | |
HqnOPIparse | JSON interface to |
See the Harlequin Extensions Manual for detailed documentation for the above keys.
files
The reference for what keys are allowed in this top-level object is specified in the schema file sw-files-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
The following is a collection of JSON keys that can be used for managing resources and other files from within a JSON configuration.
You may want to do this to install fonts, ICC profiles, halftones, and so on. You may also only want to do this per job, which is why there is a mechanism to install and delete files from a JSON config. The following keys are available:
Key | Default | Value description |
| NA | An array of strings, which may include wild cards. It’s designed to allow the local file set to be cleaned down ready for the job. |
| NA | An array of strings, which may include wild cards. It’s designed to clean up the local file set after the job is complete. |
| NA | An array of objects specifying the target filename, an array of strings for the data to be written, and an indication of encoding (raw, ASCII85 or ASCII85 over Flate). |
| NA | An array of objects, each specifying source and target file names. |
The file manipulation described here is at the RIP level, even if multiple RIPs are using the same union file system.
Some examples using the above keys are demonstrated in the following config file:
{
"$schema": "./schemas/sw-config-schema.json",
"files": {
"#1": "deletes all the files with a .jsontest suffix at the start of the job",
"DeleteFilesAtStart": [
"%os%*.jsontest"
],
"#2": "deletes all the files with a .jsontest suffix at the end of the job",
"DeleteFilesAtEnd": [
"%os%*.jsontest"
],
"#3": [
"creates three files at the top level of the SW folder:",
"- file1.jsontest contains some lines of text",
"- file2.jsontest contains PS code to list the *jsontest files",
"- file3.jsontest contains the decoded ASCII85 data"
],
"InstallFiles": [
{
"Filename": "%os%file1.jsontest",
"Data": [
"Some lines of text\n",
"which will be written to file1.jsontest\n",
"at the top level of the SW folder.\n"
]
},
{
"Filename": "%os%file2.jsontest",
"Data": [
"%!PS\n",
"% Output the names of all the *.jsontest files to the monitor\n",
"(%os%*.jsontest) { == } 2048 string filenameforall\n"
]
},
{
"Filename": "%os%file3.jsontest",
"Encoding": "ASCII85",
"Data": [
"<+oue+DGm>F)Po,+EV1>F<G[D+@/pn8P(m!+D#G#De*E3$:/Q?",
"+EV:2F!,1<+EMI<AKYi.Eb-j1"
]
}
],
"#4": "makes a copy of file1.jsontest",
"CopyFiles": [
{
"Source": "%os%file1.jsontest",
"Destination": "%os%file1.copy.jsontest"
}
]
}
}fonts
The reference for what keys are allowed in this top-level object is specified in the schema file sw-fonts-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
The fonts key is used to configure miscellaneous font-related items. Its keys are:
| Key | Default | Value description |
|---|---|---|
DefaultFont | NA | String. The default font to use in place of missing non-CID fonts. |
DefaultCIDFont | NA | String. The default font to use in place of missing CID fonts. |
MissingFonts | NA | String. The action for missing fonts: error, report, or deferred. Calls |
FontEmulation | false | Boolean. Enable / disable font emulation.
|
FontSubstitution | NA | An array of objects containing strings for the original font name and its replacement for non-CID font substitution. |
CIDFontSubstitution | NA | An array of objects containing strings for the original font name and its replacement for CID font substitution. |
imposition
The imposition key has not been implemented for Harlequin 13.1r0 but will eventually contain imposition-related configuration items such as:
HqnInitImposeandHqnInitOverlayfromHqnImpose2HqnLayoutInitialize_1fromHqnLayout
and more.
In the interim, you can call the HqnImpose2 procset directly by using the procset's JSON key, as described below.
interceptcolorspace
The reference for what keys are allowed in this top-level object is specified in the schema file sw-interceptcolorspace-schema.json which can be found in the SW/TestConfig/JSON/schemas directory.
interceptcolorspace is the JSON equivalent of the PostScript operator setinterceptcolorspace. All properties within this object retain the same property names and hierarchy as used in PostScript configurations; see PostScript LANGUAGE REFERENCE (third edition) and the Harlequin Extensions Manual for documentation on the keys and their meaning for setinterceptcolorspace.
jsonrun
The reference for what keys are allowed in this top-level object is specified in the schema file sw-jsonrun-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
An array of filenames that are run in order at the end of processing the other top-level properties. jsonrun provides a way of referencing JSON files from a configuration (for example, to allow static definitions for parts of a configuration that are commonly used to be incorporated into a dynamically generated job-level config).
{
"$schema": "./schemas/sw-config-schema.json",
"jsonrun": [
"jsonrun-1.json",
"jsonrun-2.json"
]
}Relative filenames are rooted from the directory of the file they are invoked from. The initial root directory for the -c command-line option is the SW/TestConfig folder.
Absolute filenames need to be specified using the PostScript syntax, as described under the Filenames section above.
pagedevice
The reference for what keys are allowed in this top-level object is specified in the schema file sw-pagedevice-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
pagedevice is the JSON equivalent of the PostScript operator setpagedevice. All properties within this object retain the same property names and hierarchy as used in PostScript configurations; see PostScript LANGUAGE REFERENCE (third edition) and the Harlequin Extensions Manual for documentation on the keys and their meaning for setpagedevice.
The CustomConversions key is usually set to {{}{}{}}cvlit, and doing that in JSON is supported. Any use cases that require a more complicated CustomConversions value (for example, for Photoink, are not supported directly in JSON, but may be by encapsulating the relevant parts in a PostScript and then using psrun (see below).
pdfparams
The reference for what keys are allowed in this top-level object is specified in the schema file sw-pdfparams-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
pdfparams is the JSON equivalent of the PostScript operator setpdfparams. See the PostScript LANGUAGE REFERENCE (third edition) and the Harlequin Extensions Manual for documentation on the keys and their meaning for setpdfparams.
procsets
The reference for what keys are allowed in this top-level object is specified in the schema file sw-procsets-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
An array of objects, each of which identifies a procset (ProcSet key), an entry point (Call key) to that procset, and any operands (Operands key) that must be provided to it. The procsets are executed and therefore allow OEM-specific procsets to be called.
Procsets array item keys follow:
| Key | Default | Value description |
|---|---|---|
ProcSet | NA | The filename that contains the procset as documented using the /ProcSet findresource PostScript operator. Typically, the files are located in the SW/procsets directory. |
Call | NA | The procedure within the procset. |
Operands | NA | An array of operands in the order that they would have been placed on the operand stack in a PostScript configuration, to be provided to the procset. These are, in effect, procedure arguments needed by the Call procedure. |
Although the HqnContour InitContour is dealt with specifically in the control top-level object above, the following is an example of calling it from procsets (note the new operand structure for Harlequin 13.1r0 in this example):
{
"$schema": "./schemas/sw-config-schema.json",
"procsets": [
{
"ProcSet": "HqnContour",
"Call": "InitContour",
"Operands": [
{
"Outputs": [
{
"Style": "HPGL2",
"OutputFile": [ "<JobName>", "<MM>", "<PP>", ".hpgl2"],
"Intercepts": [
{
"Mode": "AllStrokes"
}
],
"ColorAction": "PassThrough",
"OverCut": 1,
"AccurateExtend": 1,
"FilePerPage": false,
"ExportResolution": 300,
"ExportAllPages": true,
"DrawClosepath": true,
"DashAction": "Export",
"CurveFormat": "Bezier",
"FillWidth": 3,
"Flatness": 2,
"HiddenLayerAction": "Export",
"LayerComments": "Export",
"MaxDecFigs": 2,
"MaxLineLen": 1024,
"ObeyScalingAndExtraOrientation": true,
"OffsetX": 10,
"OffsetY": 10,
"PreCheck": true,
"WidthAction": "Export"
}
]
}
]
}
]
}
psrun
The reference for what keys are allowed in this top-level object is specified in the schema file sw-psrun-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
An array of filenames that are run in order at the end of processing the other top-level properties. This allows well-tested existing PostScript configuration files to continue to be used when the job config is supplied in JSON. It also allows job configuration files that require executable PostScript procedures (as opposed to a static hierarchy of key-value pairs) to continue to be used in a config. An example might be if you wish to install a SensePagedevice call, or ColorantFamilies with complex CustomConversions.
{
"$schema": "./schemas/sw-config-schema.json",
"psrun": [
"SameDirectoryAsThisJSONFile.ps",
"%os%/TestConfig/CMYKCompositeBand300dpi",
"%C%/globalsetups/MyPostScriptProgram.ps"
]
}Relative filenames are rooted from the directory of the file they are invoked from.
Absolute filenames need to be specified using the PostScript syntax, as described under the Filenames section above.
reproduction
The reference for what keys are allowed in this top-level object is specified in the schema file sw-reproduction-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
reproduction is the JSON equivalent of the PostScript operator setreproduction. All properties within this object retain the same property names and hierarchy as used in PostScript configurations; see the PostScript LANGUAGE REFERENCE (third edition) and the Harlequin Extensions Manual for documentation on the keys and their meaning for setreproduction.
screening
The reference for what keys are allowed in this top-level object is specified in the schema file sw-screening-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
The screening key is used to configure miscellaneous screening-related items. Its keys are:
| Key | Default | Value description |
|---|---|---|
InstallHalftoneDef | A halftone dictionary to install as a single screen. | |
InstallHalftoneDefsFile (Note: This key is not available in Harlequin 13.1r0.) | String, or array of strings. Install a set, or sets, of screens. |
systemparams
The reference for what keys are allowed in this top-level object is specified in the schema file "sw-systemparams-schema.json" which can be found in the "SW/TestConfig/JSON/schemas" directory.
systemparams is the JSON equivalent of the PostScript operator setsystemparams. All properties within this object retain the same property names and hierarchy as used in PostScript configurations; see the PostScript LANGUAGE REFERENCE (third edition) and the Harlequin Extensions Manual for documentation on the keys and their meaning for setsystemparams.
userparams
The reference for what keys are allowed in this top-level object is specified in the schema file sw-userparams-schema.json, which can be found in the SW/TestConfig/JSON/schemas directory.
userparams is the JSON equivalent of the PostScript operator setuserparams. All properties within this object retain the same property names and hierarchy as used in PostScript configurations; see the PostScript LANGUAGE REFERENCE (third edition) and the Harlequin Extensions Manual for documentation on the keys and their meaning for setuserparams.
Extra OEM page device parameters
Allows the OEM to specify new page device parameters. Global Graphics has supplied a minimal JSON schema (SW/TestConfig/JSON/schemas/sw-oem-extra-page-device-keys.json), but an OEM adding their own parameters would be expected to build and maintain their own, more complete, schema.
The OEM parameters get passed through the ExtraPageDeviceKeys key to pagedevice. OEM parameters are guaranteed to be set after all other pagedevice keys.
| Key | Default | Value description |
|---|---|---|
ExtraPageDeviceKeys | An object, array, string, boolean, or numeric of extra |
For example:
ExtraPageDeviceKeys
{
"$schema": "./schemas/sw-config-schema.json",
"pagedevice": {
"ExtraPageDeviceKeys": {
"RasterParams": {
"TIFF": {
"CompressionType": "LZW"
}
}
}
}
}Order of JSON processing
In a PostScript configuration, the order of operators and other calls in the config file defines the order in which they are applied; this is necessary because of some interactions between various parts of the configuration, but it does make some things non-intuitive.
One of the goals of JSON config files was to remove that order dependency, which is done by:
- The order of properties within the JSON file does not make any difference to the behavior. This is because the JSON config files are loaded as a DOM and then “smartly processed”.
- Where there are interactions between different parts of the configuration, those are handled by smart processing of the JSON config files rather than needing the JSON config author to be aware of dependencies.
To achieve this, properties are applied in a specific order:
DeleteFilesAtStartfrom files.- Hook
DeleteFilesAtEndJobintoEndJob, to be applied later. InstallFilesfrom files.CopyFilesfrom files.systemparamsuserparamspdfparamsinterceptcolorspacereproductionscreeningcolorcontrolfonts- imposition
pagedeviceOEM parametersprocsetsjsonrunpsrun
This order is designed to simplify processing as much as possible by ensuring that information required by each step is already available when it is reached. For example:
- Applying
DeleteFilesAtStartbeforeInstallFilesmeans that wild cards can be used to clean out whole directories, which are then repopulated as required for this specific job. - Applying
InstallFilesearly means that fonts, ICC profiles, and others that are needed by later steps can be made available. - Applying
pagedeviceafterinterceptcolorspaceavoids any requirement for an extra call tosetpagedeviceifOverprintPreviewis set toSpotsOnly. - Applying screening before
pagedevicemeans that appropriate halftone resources can be loaded for use asDefaultHalftoneand so on.
Order when jsonrun and psrun properties are present.
If a JSON config file includes both jsonrun and psrun properties, then all of the properties of that JSON config file are transformed and processed in order, as listed above, except for the jsonrun and psrun properties.
For each JSON config file referenced under jsonrun, the JSON config file is processed independently in the same way. If that child JSON config file includes a jsonrun property, those JSON config files are also processed independently before returning control to the parent. If the child contains a psrun property, then the list of files to be run as PostScript are appended to the list from the parent before returning.
This mechanism applies to any further descendants as jsonrun is traversed depth-first.
Only when all jsonrun files and their descendants have been processed does the accumulated list of JSON config file names for psrun get processed.
Advanced JSON configuration
How it works under the hood
JSON config files are implemented in RIP by transforming the JSON config files to PostScript and then interpreting that generated PostScript as if it were used on the command line as an argument to -c.
It is possible to view this generated PostScript, either for curiosity or as a debugging aid. This can be done by using clrip's -j option. For example:
clrip -j -c JSON/CMYKComposite300dpi.json MyTestFile1.pdf
The -j option saves a copy of the generated PostScript alongside the JSON config file. So, for example, the following command line:
clrip -j -c JSON/CMYKComposite300dpi.json /myjobs/MyTestFile1.pdf
would generate a file called:
JSON/CMYKComposite300dpi.json.ps
The generated PostScript file could in turn be used as an argument to -c. So you could use:
clrip -c JSON/CMYKComposite300dpi.json.ps /myjobs/MyTestFile1.pdf
This is potentially a useful debugging aid for OEMs who are moving from PostScript config files to JSON config files if issues are found in this technology preview. Please report any cases to Global Graphics support if the generated PostScript does not match your expectations or if using the JSON configuration results in different output to using the PostScript configuration.
Forcing PS value types from JSON string values
Mapping from JSON value types to PS types has a limitation in that PS has the concept of names, files, and binary data that do not exist in JSON. Although the Harlequin Core JSON config device has the ability within it to convert JSON string values to the appropriate type (based on key name and the JSON objects that key resides in), it may sometimes be necessary to force the translation to a certain PS type. This can be achieved using one of the following prefixes for JSON string values. If the prefix is neither /n: nor /f:, the string is passed through first and then emitted. Most of the time the string is passed through verbatim. If the /s: prefix is present, the string value is always passed through verbatim, bypassing any smart processing.
<String> in angle brackets in the table below represents whatever text string you wish to write into the JSON:
Type | Prefix | Comments |
PS string | <String> | Produces (<String>) in the PS output unless there is the ability to transform this value into the appropriate type based on the key name and the objects that key resides in. |
PS string |
| Always producse (<String>) in the PS output, bypassing any smart processing. |
PS name |
| Produces /<NameString> in the PS output. |
PS file |
| Produces (<FileName>) (r) file in the PS output (that is, a read-only |
A number of cases where parameters were required to be names in previous versions of the RIP were relaxed to allow the use of strings or names in Harlequin 13.1r0. In addition, there are a few cases, primarily in procsets, where additional mappings may be used. Examples include:
- A short in-line procedure may be included by delivering it in a string, ensuring that the first and last characters in the string are open- and closed-brace characters; this form is described as a string procedure. As an example, an empty Trailer procedure for
HqnImpose2may be written as{}. This approach should only be used for very short procedures, not including line ends. For longer procedures, define them in PostScript VM through an alternative route (for example, a file inSW/Sys/ExtraStart) and use a string procedure to reference that procedure from PostScript VM. See the Harlequin Extensions Manual for more detail on where this model may be used. - The
OutputFileparameter inHqnContourcan take an array form in which strings and names have different meanings. From 13.1r0, a string in which the value that would have been delivered as a name is surrounded by angle brackets may be used instead (for example, <JobName>.
Other issues
Text encoding
The JSON specification recommends, but does not require, strings to be encoded using UTF-8. That implies that it's OK to use other encodings when they might be more appropriate for your specific use case (including using different encodings for each string in a file), But some JSON-aware editors transform strings in other encodings into UTF-8 automatically and silently. As an example, opening a JSON file in which a string is encoded using ISOLatin1 in VS Code may transform that string to UTF-8 when the file is re-saved.
Global Graphics recommends using UTF-8 wherever possible and using care if any other encoding is required. Please let us know about any situations where you MUST use something other than UTF-8.