
(v13) Comparison of VTune one-RIP and four-RIP memory analysis
This page applies to Harlequin v13.1r0 and later; and to Harlequin Core but not Harlequin MultiRIP
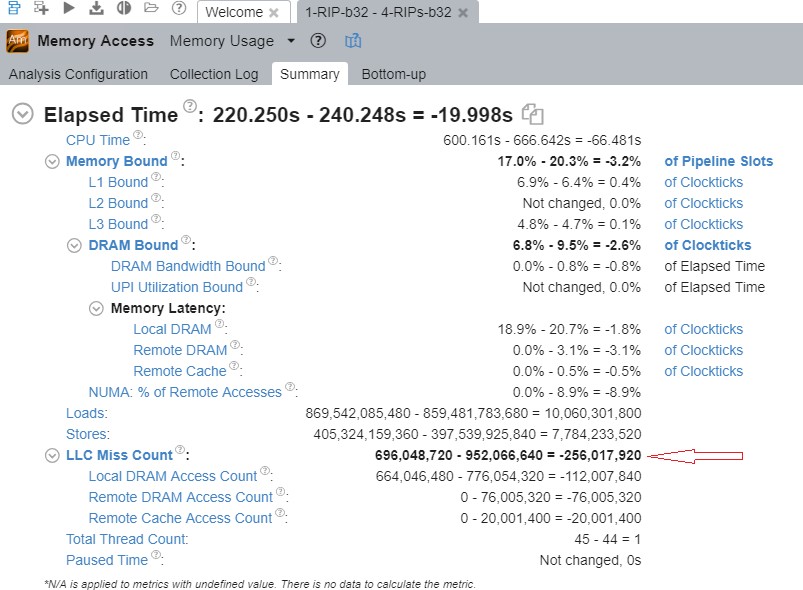
Figure: VTune memory analysis comparison: One RIP and four RIPs
Looking at the LLC Miss Count, when there are four RIPs running compared to a single RIP, there are ~256 million additional LLC (last-level caches) misses. The documentation for “LLC Miss Count” is:
“The LLC is the last, and longest-latency, level in the memory hierarchy before main memory (DRAM). Any memory requests missing here must be serviced by local or remote DRAM, with significant latency. The LLC Miss Count metric shows total number of demand loads which missed LLC. Misses due to HW prefetcher are not included.”
It would appear that the nature of the job and how the memory is distributed when processing this job across multiple RIPs is competing for the L3 cache which is shared amongst all the processor cores. So in effect there is more L3 cache contention when more RIPs are added.
This explains why each individual RIP takes more time doing the same workload as more RIPs are running simultaneously. Competing RIPs purge each other's L3 cache data and the RIPs are needing to go back to DRAM.