
(v13) Harlequin Core performance Summary
This page applies to Harlequin v13.1r0 and later; and to Harlequin Core but not Harlequin MultiRIP
Comparing “LLC Miss Counts” for the three runs we get: LLC Miss count - one RIP ~696 million
LLC Miss count - four RIPs ~952 million (~37% increase from one RIP) LLC Miss count - eight RIPs ~1,368 million (~44% increase from four RIPs)
Comparing Avg RIP time for the three runs (two rendering threads) we get: 280 seconds - one RIP
307 seconds - four RIPs (~10% longer than one RIP) 377 seconds - eight RIPs (~23% longer than four RIPs)
Comparing Avg RIP time for the three runs (four rendering threads) we get: 217 seconds - one RIP
239 seconds - four RIPs (~10% longer than one RIP) 317 seconds - eight RIPs (~32% longer than four RIPs)
Figure: Number of RIPs, LLC miss rate and the RIP time clearly shows a strong relationship between the LLC miss rate and the RIP time:
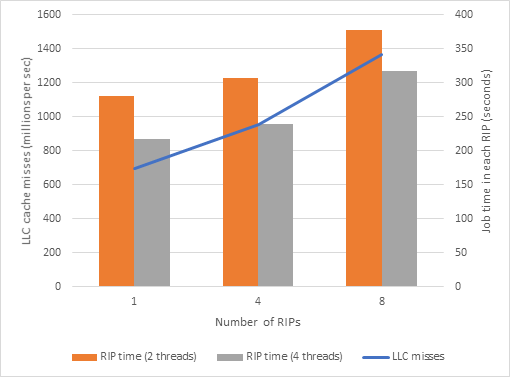
Figure: Number of RIPs, LLC miss rate and the RIP time
But the slower time per RIP does not prevent the total throughput continuing to improve with additional RIPs:
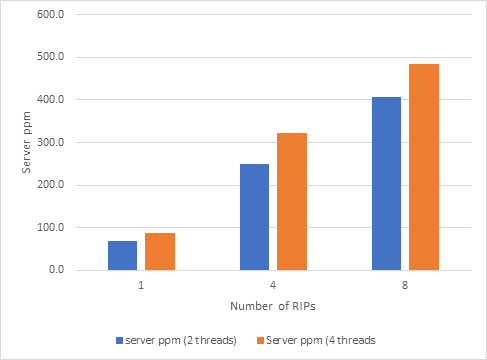
Figure: Total throughput with additional RIPs
We know that tuning MaxBandMemory so that render bands stay within a core's L2 cache can have a major improvement on RIP performance. When this is optimized by finding the “sweet spot” you can then find the optimal number of render threads. The optimal number of render threads will depend on the type of job and its complexity.
We also know that an individual RIP generally performs at its best when there is a core allocated per rendering thread and that at least one core is left to the OS.
It appears when multiple RIPs are being used the optimal performance for each individual RIP follows the same general rule, but you introduce more memory contention on the L3 cache and DRAM. How much depends on the job (such as complexity and size).
Although there does not appear to be a predictable formula between “LLC Miss Counts” and how long each RIP takes, this does seem to be the primary influencer on why each RIP takes longer.
Interpreting these recommendations has probably made it clear that a linear response, where the overall throughout speed is directly proportional to the number of RIPs, is simply not going to happen all the way up to using all of the cores available. As the number of RIPs increases, the gain per additional RIP will be lower, leading to a plateau of throughput. Increasing the number of RIPs reduces throughput as each RIP spills caches being used by other RIPs, or delays memory transfers.